

Duplicate Content Probleme zu finden, ist schon schwierig, die Behebung der Probleme umso mehr. Denn je ungenauer die Analyse, desto mehr stochert man im Nebel. Um den Prozess von Analyse und Behebung zu vereinfachen, sollen 7 Regeln für Klarheit sorgen.
Identische Inhalte sind für Suchmaschinen ein Problem. Warum sollte eine Suchmaschine dieselben Inhalte mehr als einmal im Index haben? Um Ressourcen zu sparen, versuchen also Suchmaschinen, doppelte Inhalte nicht zu indexieren. Doch was ist das Original und was ist eine Kopie? Generell verursacht Duplicate Content (kurz „DC“) Probleme bei den Platzierungen, daher sollte man vermeiden, dass eine Suchmaschine solche doppelten Inhalte findet. Die Ursache ist aber unterschiedlich: Zum einen können Inhalte tatsächlich doppelt vorhanden sein (beispielsweise ein Artikel in einem Shop, der in mehreren Kategorien enthalten ist), zum anderen kann es aber auch rein technische Gründe dafür geben. Vor allem dann, wenn eine Seite über mehrere Adressen erreichbar ist.
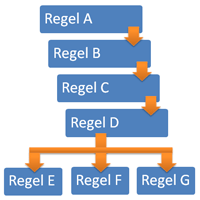
Die Abbildung zeigt den logischen Ablauf der Regeln. Die ersten Regeln folgen aufeinander. Greifen alle 4 Regeln nicht, gibt es drei weitere Regeln, die nach dem ODER Prinzip greifen.
Vorweg ein wichtiger Hinweis: Diese Ausführungen beziehen sich nur auf Duplicate Content auf der eigenen Website. Eine Ausweitung auf Inhalte im Web ist natürlich möglich. Die Behebung von DC Problemen erfolgt aber nach anderen Regeln, da man auf Inhalte auf dritten Websites nur selten Zugriff hat.

Mit Hilfe der Software Forecheck lässt sich Duplicate Content schnell und leicht ermitteln. Nicht immer sind die Ergebnisse aber eindeutig und klar. Daher sollen 7 Regeln helfen, die Ursache nachvollziehbar zu machen. Dies vereinfacht das Verstehen des Problems und die Behebung. Zunächst soll erklärt werden, wie Forecheck bei der Ermittlung von DC vorgeht, damit man die einzelnen Prozesse besser versteht. Die folgenden Ausführungen beziehen sich auf die Analyse und Ausgabe der Daten in Forecheck. Alle 7 Regeln werden weiter unten definiert und erklärt.
Forecheck sucht im <head> aller Seiten, sprich (X)HTML Dokumenten, nach einem Canonical Link. Wird dort keiner gefunden, wird im HTTP Header nach einem gesucht. Wenn es sich nicht um eine Seite handelt, dann sucht Forecheck nur im HTTP Header, beispielsweise bei PDF Dokumenten.
Die Regeln A-G erklären die Ergebnisse für jede Zeile und werden hier genau erläutert. Zunächst sollen einzelne (Spalten-)werte definiert werden:
Canonical Link (absolute URL): Die URL des Canonical Links. Diese wird immer in eine absolute URL umgewandelt, wenn die URL relativ ist. Dies erleichert es, zu verstehen, welche Auswirkungen der Canonical Link hat. Beachten Sie also bitte, dass der Link im Quellcode selbst möglicherweise abweicht und relativ angegeben ist! Dieses Feld wird farblich hinterlegt, je nachdem was die Auswertung der Daten ergibt.
Status (Canonical): Status-Code der URL des Canonical Links. Ist kein Canonical Link vorhanden, ist dieses Feld leer. Bitte beachten Sie, dass die URL des Canonical Links analysiert sein muss, damit hier ein Status Code stehen kann. Im unten stehenden Beispiel wurde die URL des Canonical Links noch nicht analysiert. Dies erkennen Sie an der Spalte Status. So lange hier „pending“ steht, wurde die URL des Canonical Links noch nicht analysiert. Sie müssen dann die Analyse weiter laufen lassen, bis der Index dieser Canonical URL analysiert worden ist.

Robots (Canonical): Die Information wie im Feld Robots weiter vorne, hier aber für die URL des Canonical Links
Es gibt viele mögliche Probleme bezüglich Duplicate Content und viele Wege, das Problem zu beheben. Hier sollen ein paar Hinweise gegeben werden, um das Problem und die möglichen Lösungswege zu verstehen.
Forecheck vergleicht stets den Inhalt aller Seiten miteinander. Forecheck kann auch nur die Seiten innerhalb einer Domain miteinander vergleichen. Es werden derzeit keine identischen Inhalten im Internet ermittelt, ist aber geplant. Derzeit können auch nur identische Inhalte ermittelt werden, keine sehr ähnlichen Inhalte.
Wie entsteht Duplicate Content?
Grundsätzlich kann es viele mögliche Ursachen für Duplicate Content geben:
– Die gleich Seite ist über eine andere URL erreichbar (unterscheiden sich z.B. nur durch einen Parameter). Beispiel:
www.beispiel.de/seo/suchbegriffe/
www.beispiel.de/seo/suchbegriffe/?lang=de
www.beispiel.de/seo/suchbegriffe/?p=print
www.beispiel.de/seo/suchbegriffe/?sess=78tg8dg7ew8igwedf
– Zwei Seiten haben den gleichen Inhalt (Beispiel: Ein Artikel in einem Shop ist in mehreren Kategorien enthalten)
www.beispiel.de/herren/hosen/?artikel=67567
www.beispiel.de/jeans/stretch/?artikel=56563
Anderes Beispiel: Seite für mehrere Länder aber mit gleichem Inhalt:
www.beispiel.de/DE-AT/press
www.beispiel.de/DE-DE/press
www.beispiel.de/DE-CH/press
Lösungsansätze gibt es mehrere:
Seiten von der Indexierung ausschließen (mittels Meta-Tag oder robots.txt): Das ist prinzipiell eher die schlechteste Lösung, denn dadurch wird Linkpopularität „vernichtet“. Denn die Seiten die nicht indexiert werden haben eingehende Links und ausgehende Links. Die ausgehenden Links werden aber nicht gewertet, was die Linkpopularität aller Seiten innerhalb einer Domain reduziert.
Weiterleitungen einrichten (per 301): Dies macht natürlich nur Sinn, wenn die Inhalte tatsächlich gleich sind.
In den Webmaster Tools Parameter ausschließen: Hier kann man Google anweisen, dass bestimmte Parameter keinen Einfluss auf den Inhalt haben oder den Inhalt nur modifizieren. Dies kann sinnvoll eingesetzt werden, es muss aber geprüft werden, ob das Problem dadurch wirklich gelöst wird. Sie können in den Einstellungen von Forecheck diese Einstellungen nachbilden und testen, wie die Indexierung dann verläuft. Dort gibt es eine Funktion, Parameter während der Indexierung auszuschließen. Beachten Sie bitte, dass dies nicht rückwirkend möglich ist, sondern vor dem Start einer Analyse eingegeben sein muss.
In den Webmaster Tools Ordner verschiedenen Zielländern zuordnen: Wenn mehrere Ordner den selben Inhalte haben (z.B. einmal für Deutschland, einmal für Österreich) und diese dann verschiedenen Zielländern zugewiesen wurden, werden diese nicht als Duplicate Content angesehen. Sie können in Forecheck derzeit keine Zielländer für Ordner definieren, Sie können aber die Analyse auf mehrere Unterordner eingrenzen oder bestimmte Unterordner ausschließen, um das zu prüfen. Diese Möglichkeit finden Sie ebenfalls im Tabreiter Einstellungen.
Canonical Link nutzen: Diese Option wurde 2009 von den wichtigsten Suchmaschinen ins Leben gerufen und ist seit 2012 auch Teil des offiziellen Standards (RFC 6596). Dies ermöglicht Google Informationen darüber zu geben, welche URL „das Original“ ist und welche ein Duplikat.
Prinzipiell kann man keine allgemein gültigen Regeln aufstellen, wie man Duplicate Content löst. Am besten ist es, es entsteht erst gar kein Duplicate Content. Hierzu sollte man zunächst prüfen, wie man durch technische Maßnahmen die Entstehung verhindert, bevor man versucht, den Suchmaschinen Hinweise zu geben.
Sobald Suchmaschinen anfangen, selber zu interpretieren, was nun in den Index soll, besteht immer die Gefahr, dass Google Seiten nicht indexiert, die vielleicht wichtig sind oder die auch Verlinkungen haben, die nicht gewertet werden. Auch wenn von den Suchmaschinen beteuert wird, man hätte das im Griff, zeigt die Praxis, dass das vermeiden und lösen dieses Problems oft deutlich die Platzierungen verbessert.
Typische Beispiele für Duplicate Content
Folgendes Bild zeigt ein typisches Beispiel für eine Seite, die über mehrere URLs erreichbar ist:

Ein Canonical Link wird nicht verwendet (gelb hinterlegte Felder). Dieses Problem lässt sich durch einen Canonical Link sehr gut lösen.
Zusätzlich zeigt Forecheck an, ob eine URL überhaupt indexiert wird. Es gibt viele mögliche Konstellationen der einzelnen Werte, daher kann hier nur exemplarisch erläutert werden, wann Forecheck das Problem als gelöst ansieht (der Canonical Link ist dann auch grün hinterlegt).

Alle URLs mit dem selben Inhalt haben die gleiche Canonical URL. Diese Canonical URL selbst hat auch den selben Inhalt, ist also Teil der URLs mit dem selben Inhalt.
Dann kann man gesichert sagen, dass der Canonical Links das Problem eindeutig für eine Suchmaschine löst.
Hier ein weiteres Beispiel das zeigt, dass häufig die Daten nicht eindeutig sind:
Im folgenden Bild sieht man, dass die mittlere URL ein Problem ist, weil der Canonical Link hier anders ist als bei den anderen beiden URL. Andererseits wird diese URL von der Indexierung ausgeschlossen. Würde man diese URL also nicht berücksichtigen, wäre das DC Problem gelöst. Allerdings wurde Forecheck so eingestellt, dass Forecheck zwar die robots.txt berücksichtigen aber ignorieren soll.
Würde man die Einstellung ändern und sagen, Forecheck soll die robots.txt berücksichtigen und nicht ignorieren, wäre die URL von der Indexierung ausgeschlossen. Dann würde diese hier auch nicht erscheinen und in diesem Fall wäre die mittlere URL nicht bei dieser Analyse dabei. Dann wäre das DC Problem gelöst und die Canonical Links wären grün unterlegt.
Die Daten der Auswertung müssen stets im Kontext betrachtet und ausgewertet werden. Forecheck ist ein Werkzeug, um diese Daten zu erfassen und zu analysieren. Es kann aber nicht immer ein klarer Lösungsvorschlag ermittelt werden, da es viele Faktoren und Möglichkeiten gibt, das Duplicate Content Problem zu lösen.

Die Regeln sollen Ihnen helfen zu verstehen, wie Forecheck die Daten für Duplicate Content auswertet.
Sie finden daher zu jeder Zeile in dem Duplicate Content Report einen Hinweis auf die angewendete Regel.
Grundsätzlich gilt: Forecheck kann nur die Informationen auswerten, die vorliegen. Wenn also zusätzlich noch Angaben in den Google Webmaster Tools gemacht wurden, um einzelne Parameter aus den URLs zu entfernen, sollten diese in Forecheck auch berücksichtigt werden. Dies ist im Tab Einstellungen möglich unter „URL Verarbeitung“.
Die Regeln werden in Ihrer Reihenfolge auch abgearbeitet, also beginnend von Regel A bis Regel G. Die Regel, die für eine Zeile im Report greift, wird daneben geschrieben. Es ist denkbar, dass für eine Zeile mehr als eine Regel greifen, dann werden auch alle Regeln angegeben.
Abkürzungen: CL = Canonical Link
Duplicate Content Regel A
Ist eine URL von der Indexierung ausgeschlossen (Spalte Robots der URL), wird der CL gar nicht ausgewertet, daher ist die Zelle grau hinterlegt.

Dies gilt für jede Zeile, in denen die Indexierung unterbunden wird, unabhängig von den Daten der anderen Zeilen in einem Block an identischen Inhalten.
Sie können Forecheck anweisen, dass bei der Analyse alle Angaben für die Indexierung in Robotx.txt oder im Meta-Tags robots nicht ignoriert werden sollen.
Dann würden URLs, die von der Indexierung ausgeschlossen sind, auch nicht indexiert werden. Diese würden dann im Duplicate Content Bericht gar nicht erst erscheinen.
Die Einstellungen bezüglich der robots Daten können im Tab Einstellungen unter „Allgemein“ geändert werden.
Duplicate Content Regel B
(greift nur, wenn Regel A nicht greift)

Ist die URL des CL von der Indexierung ausgeschlossen, wird der vorhandene CL orange hinterlegt, er wird nicht weiter geprüft.
Dass der CL von der Indexierung ausgeschlossen ist, erkennt man an der rot hinterlegten Zelle „Robots (Canonical)“ (Spalte ganz rechts im Bild).
Duplicate Content Regel C
(greift nur, wenn Regeln A und B nicht greifen)
![]()
Enthält der CL eine URL die nicht Teil des Blocks mit gleichen Inhalten ist, wird diese gelb hinterlegt. Dieser Fall bedeutet, dass die URL des CL nicht den selben Inhalte hat wie alle URLs in diesem Block, also alle URLs die links in der Spalte URL stehen von diesem Block. Daher kann Forecheck nicht entscheiden, ob dieses Ergebnis richtig oder falsch ist. Hier sollte manuell geprüft werden, ob der Inhalt des CL tatsächlich auch der kanonische Inhalt ist. Der CL darf übrigens auch auf eine externe URL verweisen. Dann kann Forecheck sowieso nicht prüfen, ob der Inhalt gleich ist, weil der Inhalt von externen URLs nicht komplett von Forecheck geprüft wird.
Duplicate Content Regel D
(greift nur, wenn Regeln A bis C nicht greifen)

Enthält der CL keine URL, wird die Zelle gelb hinterlegt. Es kann hier noch nicht entschieden werden, ob dies richtig oder falsch ist. Sind wie in dem Bild aber mindestens 2 leere CL in einem Block, so löst der CL nicht das Duplicate Content Problem. Da die Abarbeitung der Zeilen einzeln erfolgt, werden die Zellen nachträglich nicht noch rot hinterlegt. Es besteht durchaus die Möglichkeit, dass das Duplicate Content Problem durch andere Maßnahmen gelöst ist, beispielsweise durch Einstellungen in den Google Webmaster Tools.
Die folgenden Regeln werden erst geprüft, wenn die Regeln A-D geprüft wurden. Die folgenden Regeln treten unter bestimmten Bedingungen in Kraft und können je nach Kombination der Daten in einem Block auch parallel gelten.
Sie werden auch nur noch für die Zeilen durchgeführt, bei denen die Regeln A-D nicht greifen!
Duplicate Content Regel E
Bedingung: In einem Block haben alle Zeilen einen CL oder höchstens eine Zeile hat keinen CL.
Bitte beachten Sie, dass nur die Zeilen eines Blocks ausgewertet werden, für die Regel A-D nicht zutreffen!

Wenn alle Zeilen einen CL haben, müssen diese identisch sein. Weichen die CL voneinander ab, ist die Angabe nicht eindeutig.
Wenn eine Zeile keinen CL hat, müssen alle anderen CL auf die URL verlinken, die den fehlenden CL hat. Nur dann sind die Angaben eindeutig.
Zudem müssen die CL im Block als URL enthalten sein (im Bild zweite Spalte von links).
In dem obigen Beispiel haben alle Zeilen einen CL, er ist gleich und sie verweisen auf die URL der ersten Zeile in dem Block.
Würde der CL der ersten Zeile in dem Block fehlen, wäre der Block dennoch ok, da die Angaben eindeutig sind.

In dem Bild oben hat nun die dritte Zeile von oben eine andere URL. Diese ist gemäß Regel C gelb markiert, da diese URL nicht Teil des Blocks ist, also nicht als URL in dem Block in der zweiten
Spalte von links vorkommt. Hier kann Forecheck nicht entscheiden, ob die Angaben korrekt sind oder nicht. Es liegt nahe, dass der CL der Zeile 3 geändert werden muss, so dass alle CL in dem
Block gleich sind.

In dem Bild gibt es nun 3 Zeilen, die auf eine URL verweisen, die nicht Teil des Blocks sind. Daher sind diese 3 Zeilen nach Regel C gelb hinterlegt. Bei den restlichen beiden Zeilen greift Regel E.
Denn es bleiben 2 Zeilen übrig, von denen eine leer ist. Beide sind grün hinterlegt, da diese prinzipiell das Problem des gesamten Blocks lösen könnten. Hierzu müssten die 3 gelb hinterlegten Zeilen
korrigiert werden.

In dem Bild gibt es nun nur eine Zeile, in der die URL des CL nicht Teil des Blocks ist, deswegen ist diese Zeile, die letzte, gelb hinterlegt. Bei den verbleibenden 3 Zeilen ist mehr als eine leer,
somit werden die Zeilen alle orange hinterlegt um den Fehler sichtbar zu machen. Hier kann auch ansatzweise nicht erkannt werden, was das Duplicate Content Problem lösen könnte.

Im nun letzten Beispiel zu Regel E gibt es eine Kombination von noch mehr Regeln. Regel A greift bei der zweiten und der letzten Zeile, weil hier die URL des Blocks von der Indexierung ausgeschlossen ist. Die erste und die dritte Zeile haben eine URL die nicht Teil des Blocks sind, also nicht in der zweiten Spalte von links zu finden sind. Daher sind diese beiden Zeilen gelb hinterlegt. Die verbleibenden beiden Zeilen sind grün, weil beide CL gleich sind und auch die URLs Teil des Blocks sind.
Duplicate Content Regel F
Bedingung: In einem Block gibt es mehr als einen leeren CL, so werden alle Zeilen des Blocks orange markiert, da dies ein Fehler ist.
Bitte beachten Sie, dass nur die Zeilen eines Blocks ausgewertet werden, für die Regel A-D nicht zutreffen!

In dem obigen Beispiel verweist die letzte Zeile in dem Block auf eine URL die nicht Teil des ganzen Blocks ist, sprich die URL des CL ist nicht in der zweiten Spalte von links enthalten. Gemäß Regel C ist dieser CL dann gelb markiert. Von den restlichen 3 Zeilen hat nur eine einen CL, daher werden alle 3 CL orange markiert.
Duplicate Content Regel G
Bedingung: Alle CL sind gefüllt, verweisen aber nicht auf den selben CL, so werden alle CL orange markiert, da dies ein Fehler ist.
Bitte beachten Sie, dass nur die Zeilen eines Blocks ausgewertet werden, für die Regel A-D nicht zutreffen!

In dem obigen Beispiel sind alle CL gefüllt, aber Sie verweisen auf verschiedene URLs. Beachten Sie: Alle URLs der CL sind auch URLs des Blocks, denn wäre ein CL nicht als URL Teil des Blocks, wäre dieser CL dann gemäß Regel C gelb hinterlegt.
Zu beachten ist, dass diese Regel unabhängig davon gilt, ob die CLs auf sich gegenseitig verweisen oder eine Kette bilden. Alle diese Fälle werden als Fehler gewertet. Ein CL sollte das Duplicate Content Problem immer direkt und eindeutig lösen. Auch Suchmaschinen werden einem CL nicht wie Weiterleitungen mehrfach folgen um zu prüfen, ob die Angaben eine Lösung herbeiführen.

